|
|
|||||
| Home | Publications | Teaching | Repository |

|
|

| |||||
This page lists a selection of the research and thesis projects in which I am – or have been – participating. Please contact me if you need additional information about any of these projects.
Moreover, our research group always has student projects available on a wide range of topics, from interesting applications to mobile ground and air robots, to analytical projects on control and estimation for the more mathematically inclined. We are looking for motivated, capable students ready to invest themselves fully into the project starting early on (for instance, in Bachelor year 3 or Master year 1). An up-to-date list of projects can be found on our group's website: open projects at ROCON. Of course, original project ideas from students are also more than welcome.
Ongoing research grants
-
Horizon Europe IA project: SeaClear2.0 - Scalable Full-Cycle Marine Litter Remediation in the Mediterranean: Robotic and Participatory Solutions
Start: January 2023 End: December 2026 (ongoing)
Participants: Lucian Busoniu, partner PI; Levente Tamas, team member; Tassos Natsakis, team member; Mihalis Maer, team member; David Rete, team member.
 Description:
Today's oceans contain roughly 25 million tons of plastic waste. SeaClear2.0 continues our efforts into marine litter search and collection. The project will improve on the existing, SeaClear team of unmanned underwater, surface and aerial vehicles, so that the system is able to search for deeper litter, in darker waters, and then pickup larger litter items. Several fully new robots are being developed: a large grapple for litter pickup, a team of surface collectors, and a smart tender for litter deposition. Methodology and software will also have to be improved, and the project has a significant component of public empowerment and participation. The project budget is about 9 million EUR, cofunded by the EU, and our team belongs to a partnership of 13 institutions, under the coordination of the Delft University of Technology.
Description:
Today's oceans contain roughly 25 million tons of plastic waste. SeaClear2.0 continues our efforts into marine litter search and collection. The project will improve on the existing, SeaClear team of unmanned underwater, surface and aerial vehicles, so that the system is able to search for deeper litter, in darker waters, and then pickup larger litter items. Several fully new robots are being developed: a large grapple for litter pickup, a team of surface collectors, and a smart tender for litter deposition. Methodology and software will also have to be improved, and the project has a significant component of public empowerment and participation. The project budget is about 9 million EUR, cofunded by the EU, and our team belongs to a partnership of 13 institutions, under the coordination of the Delft University of Technology.
-
PNRR DECIDE: AI design of decentralized coopetitive control over networks
Start: July 2023 End: June 2026 (ongoing)
Description: The DECIDE research project will develop a new unified methodology for decentralized coopetitive control of systems interconnected over networks. Coopetitive interconnected systems blend together competition — each system has its individual cost to optimize — with cooperation in order to reach a coherent synchronized behavior. Due to the lack of precise knowledge on the system's dynamics and on the interconnection topology, we will use machine learning techniques from artificial intelligence (AI) to design agile control strategies. The efficiency of the fundamental results obtained during the project will be validated in high-societal-impact case studies including robotics, epidemics control and climate change planning.
The DECIDE research project will develop a new unified methodology for decentralized coopetitive control of systems interconnected over networks. Coopetitive interconnected systems blend together competition — each system has its individual cost to optimize — with cooperation in order to reach a coherent synchronized behavior. Due to the lack of precise knowledge on the system's dynamics and on the interconnection topology, we will use machine learning techniques from artificial intelligence (AI) to design agile control strategies. The efficiency of the fundamental results obtained during the project will be validated in high-societal-impact case studies including robotics, epidemics control and climate change planning.
Finalized research grants (selection)
-
H2020 RIA project: SeaClear - Search, Identification, and Collection of Marine Litter with Autonomous Robots
Start: January 2020 End: December 2023 (ongoing)
Participants: Lucian Busoniu, partner PI; Levente Tamas, team member; Tassos Natsakis, team member; Mihalis Maer, team member; Matthias Rosynski, team member; Bilal Yousuf, team member.
 Description:
Litter disposal and accumulation in the marine environment is one of the fastest growing threats to the world's oceans. Plastic is the most common type of litter found on the seafloor, but the list is long and includes glass, metal, wood and clothing. The EU-funded SeaClear project is developing autonomous robots for underwater littler collection using new debris mapping, classification, and collection systems. Specifically, the project will build a mixed team of unmanned underwater, surface and aerial vehicles to find and collect litter from the seabed. The project plans to use aerial vehicles to study the correlation between surface and underwater litter. The underwater vehicles will be fitted with a combined suction and gripper device for both small and large waste. The project budget is about 5 million EUR, funded by the EU, and our team belongs to a partnership of 8 institutions, under the coordination of the Delft University of Technology.
Description:
Litter disposal and accumulation in the marine environment is one of the fastest growing threats to the world's oceans. Plastic is the most common type of litter found on the seafloor, but the list is long and includes glass, metal, wood and clothing. The EU-funded SeaClear project is developing autonomous robots for underwater littler collection using new debris mapping, classification, and collection systems. Specifically, the project will build a mixed team of unmanned underwater, surface and aerial vehicles to find and collect litter from the seabed. The project plans to use aerial vehicles to study the correlation between surface and underwater litter. The underwater vehicles will be fitted with a combined suction and gripper device for both small and large waste. The project budget is about 5 million EUR, funded by the EU, and our team belongs to a partnership of 8 institutions, under the coordination of the Delft University of Technology.
-
Young Teams project: AIRGUIDE - A Learning Aerial Guide for the Elderly and Disabled
Start: May 2018 End: June 2020
Participants: Lucian Busoniu, PI; Levente Tamas, team member; Alexandru Codrean, team member; Ioana Lal, team member.
 Description: Robotic assistants can greatly improve the life of the ever-increasing elderly and disabled population. AIRGUIDE develops aerial assistive technology for independent mobility of an elderly or disabled person over a wide, outdoor area, via monitoring risks and guiding the person when needed. Our fundamental approach is to develop a novel learning and planning control framework, by exploiting interdisciplinary, artificial-intelligence and control-theoretic insights. The framework is implemented and validated in a case study where an at-risk person is monitored outdoors, warned about risks like falling and unsafe areas, and actively guided to safety or a desired destination when required. The project was funded under the Young Teams program of UEFISCDI, for a total budget of about 100 000 EUR.
Description: Robotic assistants can greatly improve the life of the ever-increasing elderly and disabled population. AIRGUIDE develops aerial assistive technology for independent mobility of an elderly or disabled person over a wide, outdoor area, via monitoring risks and guiding the person when needed. Our fundamental approach is to develop a novel learning and planning control framework, by exploiting interdisciplinary, artificial-intelligence and control-theoretic insights. The framework is implemented and validated in a case study where an at-risk person is monitored outdoors, warned about risks like falling and unsafe areas, and actively guided to safety or a desired destination when required. The project was funded under the Young Teams program of UEFISCDI, for a total budget of about 100 000 EUR.
-
Young Teams project: Reinforcement learning and planning for large-scale systems
Start: May 2013 End: September 2016
Participants: Lucian Busoniu, principal investigator; Levente Tamas, team member; Elod Pall, team member.
 Description:
Many controlled systems, such as robots in open environments, traffic and energy networks, etc. are large-scale: they have many continuous variables. Such systems may also be nonlinear, stochastic, and impossible to model accurately. Optimistic planning (OP) is a paradigm for general nonlinear and stochastic control, which works when a model is available; reinforcement learning (RL) additionally works model-free, by learning from data. However, existing OP and RL methods cannot handle the number of variables required in large-scale systems. Therefore, this project developed a planning and reinforcement learning framework for large-scale system control. On the OP side, methods were developed to deal with large-scale actions and next states. An approach that accelerates large-scale OP by integrating RL was also designed. The methods were validated theoretically as well as in applications, with an application focus on assistive robotics for mobile manipulation. This project was funded under the Young Teams program of the Romanian Authority for Scientific Research, via UEFISCDI (number PNII-RU-TE-2012-3-0040), for a total budget of 180 000 EUR.
Description:
Many controlled systems, such as robots in open environments, traffic and energy networks, etc. are large-scale: they have many continuous variables. Such systems may also be nonlinear, stochastic, and impossible to model accurately. Optimistic planning (OP) is a paradigm for general nonlinear and stochastic control, which works when a model is available; reinforcement learning (RL) additionally works model-free, by learning from data. However, existing OP and RL methods cannot handle the number of variables required in large-scale systems. Therefore, this project developed a planning and reinforcement learning framework for large-scale system control. On the OP side, methods were developed to deal with large-scale actions and next states. An approach that accelerates large-scale OP by integrating RL was also designed. The methods were validated theoretically as well as in applications, with an application focus on assistive robotics for mobile manipulation. This project was funded under the Young Teams program of the Romanian Authority for Scientific Research, via UEFISCDI (number PNII-RU-TE-2012-3-0040), for a total budget of 180 000 EUR.
Ongoing thesis projects
-
PhD: Optimal sensing using control
Start: October 2017 End: September 2020
Participants: Zoltan Nagy, PhD candidate; Lucian Busoniu, advisor; Zsofia Lendek, advisor.
Description: Control and estimation are two major pillars of the systems and control field. However, the two problems are usually treated separately: first, an estimator is designed to recover system variables that are not measurable with the available sensors (or are measurable but only with uncertainty), and then a controller is found that takes the recovered variables as feedback, and produces a command signal for the system so as certain control objectives are satisfied. In this project, we take a different perspective: the control design will be performed in a way that optimizes sensing quality. In particular, we will consider scenarios where a separate sensor system monitors a target system, with an error that depends on the difference between the states of the two systems. Examples include two unmanned aerial vehicles (drones), one of which is following the other, or two subsequent road vehicles in an automated platooning system. Then, we aim to design at the same time an observer and controller for the sensor such that the state of the target is accurately recovered, which implicitly requires that the measurement error is minimized. This framework where the sensor is actively controlled in order to observe the target well is called for instance active sensing or active perception in robotics, but is largely unexplored in systems and control.
-
PhD: Active perception methods in collaborative robotics
Start: October 2017 End: September 2020
Participants: Daniel Mezei, PhD candidate; Lucian Busoniu, advisor; Levente Tamas, advisor.

Description: This is a sister project of the above, where we consider explicitly active perception for robotics. Whereas the project above uses control-theoretic design and analysis techniques, here we will focus on artificial intelligence tools, specifically so-called partially observable Markov decision processes. These allow specifying uncertainty in sensing, and by appropriately modeling the problem, decision-making so as to optimize the combined objective of reducing uncertainty and actually solving the control problem. We will exploit and develop further state-of-the-art solution techniques from the planning class. Two applications will be considered. In the first, a robot must sort objects traveling on a conveyor belt into different classes, but the classifier is inaccurate, and this uncertainty is modeled using a POMDP. For the second application, we will solve a task involving a human user, and use POMDPs to model uncertainty in the behavior of the human.
-
PhD: Deep learning for observation prediction
Start: March 2019 End: September 2022
Participants: Cosmin Ginerica, PhD candidate; Sorin Grigorescu, advisor; Lucian Busoniu, collaborator.
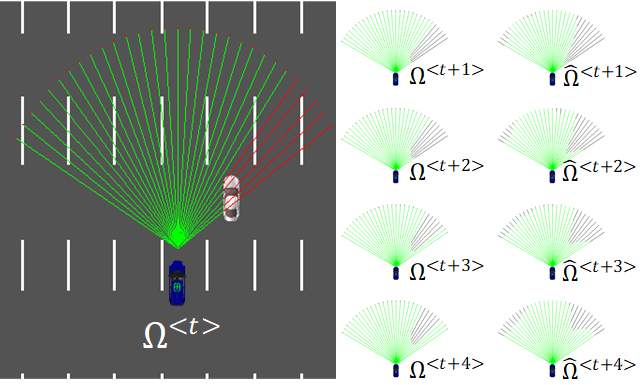
Description: This project is led by the Transylvania University of Brasov, and is the fruit of a collaboration with the RoVisLab there. We study methods for predicting an autonomous vehicle's future observations, based on historical environment data and control actions. Our first attempt adapts a recent temporal deep neural network structure that estimates the future observations of a target agent, based on sequences of previous observations, as well as on an internal model created within the network itself. We evaluate our methods in simulation, as well as for a real model car.
-
PhD: Learning closed-loop control of gamma oscillations in the visual cortex
Start: October 2019 End: September 2022
Participants: Ioana Lal, PhD candidate; Lucian Busoniu, advisor; Raul Muresan, advisor.
Description: This project is a collaboration with the Transylvanian Institute of Neuroscience, and is coadvised by the director of that Institute, Raul Muresan. Latest advances in neuroscience suggest that closed-loop control is key to elicit interesting behaviors in the cortex, and to thereby advance the understanding of the brain. We will design closed-loop control strategies to control gamma oscillations in the visual cortex, by the manipulation of visual stimuli. Since accurate models are in fact impossible to obtain, machine learning techniques will be exploited to design black-box control strategies. We will begin by simulation tests on rough, qualitative models, followed by real experiments on mice.
Finalized thesis projects (selection)
-
PhD: Learning control for power-assisted wheelchairs
Start: October 2016 End: November 2019
Participants: Guoxi Feng, PhD candidate; Thierry Marie Guerra, advisor; Sami Mohammad, co-advisor; Lucian Busoniu, co-advisor.

Description: Advances in medical research will be able to offer solutions to some of the disabilities considered irreversible today. With an elderly population estimated at over 2 billion in 2050, the issue of mobility is fundamental. Today's existing solutions, for example wheelchair manual, electric and/or assistance tools, do little to address the highly heterogeneous population of the disabled or are not suited to ageing. In this project we therefore seek innovative solutions that adapt to each person according to their disability, as well as to changes in the particular disability of each person (intra-individual component), both in the long term (for example degeneration) and in the short term (fatigue for example). We will use available measurements to estimate relevant unmeasured variables for control (virtual sensors) using unknown input observer techniques, and control algorithms based on reinforcement learning techniques to eliminate the need for precise models. Real-time experiments will be used in order to validate the theoretical approaches. In particular, we will cooperate with SME Autonomad Mobility, which has significant expertise in the mobility of disabled people.
-
PhD: Stability analysis of discounted optimal control problems
Start: October 2016 End: December 2019
Participants: Mathieu Granzotto, PhD candidate; Romain Postoyan, advisor; Jamal Daafouz, advisor; Dragan Nesic, co-advisor; Lucian Busoniu, co-advisor.
Description: Artificial intelligence is rich in algorithms for optimal control; for example, the entire field of reinforcement learning is concerned with designing such algorithms when the model of the system is unknown. However, a fundamental question remains unanswered for these AI approaches: stability. In this project, we will therefore study the stability of nonlinear systems when controlled by such algorithms. To this end, we must build a bridge between control theory and artificial intelligence. We will study in particular optimal control problems over an infinite horizon where the costs are discounted. We begin by considering the fully optimal solution, after which we will include approximation errors made by practical, numerical algorithms that use a model. The ultimate goal is to analyze reinforcement learning algorithms that are model-free.
-
PhD: Nonlinear control for commercial drones in autonomous railway maintenance
Start: October 2013 End: September 2016
Participants: MSc Koppany Mathe, PhD candidate; Lucian Busoniu, co-advisor; Prof. Liviu Miclea, advisor; Dr. Laszlo Barabas, industry consultant; Prof. Jens Braband, industry consultant.
Description: Drones are getting widespread and low-cost platforms already offer good flight and video recording. This project uses such drones in the context of railway maintenance by developing applications for autonomous navigation in railway environment. The primary focus of the project is to perform vision-based navigation for infrastructure inspection. Using the libraries of ROS and OpenCV, object detection methods (using feature detectors, optical flow, classifiers,...) are studied and implemented for target detection, target/rail track following and obstacle detection purposes. These methods will serve for basic demonstrative use-cases, showing the autonomy of drones in short-range inspection and long-range track following applications. Furthermore, building upon the above vision-based navigation toolset that we implement, optimization techniques are developed and evaluated for the flight trajectory tracking and planning tasks. In this context, we will investigate commonly used planning methods like RRT or MPC techniques and compare them to the novel optimistic planning algorithms. Specifically, we focus on developing methods for planning under communication or computational constraints, common situations in remote control applications or in case of lightweight drones. This project is supported by a grant from Siemens, reference no. 7472/3202246859 and is part of the international Rail Automation Graduate School (iRAGS).
-
PhD: Online model learning algorithms for actor-critic control
Start: December 2009 End: March 2015
Participants: MSc Ivo Grondman, PhD candidate; Lucian Busoniu, co-advisor; Prof. Robert Babuska, promotor.
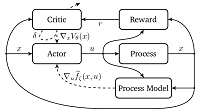
Description: Although RL is in principle meant to be completely model-free, the absence of a model implies that learning will take a considerably long time as a lot of system states will have to be visited repeatedly to gather enough knowledge about the system such that an optimal policy may be found. A main challenge in RL is therefore to use the information gathered during the interaction with the system as efficiently as possible, such that an optimal policy may be reached in a short amount of time. This project aims at increasing the learning speed by constructing algorithms that search for a relation between the collected transition samples and use this relation to predict the system's behaviour from this by interpolation and/or extrapolation. This relation is in fact an approximation of the system's model and as such this particular feature is referred to as 'model learning'. Furthermore, if (partial) prior knowledge about the system or desired closed-loop behaviour is available, RL algorithms should be able to use this information to their advantage. The final approach to speed up learning addressed in this thesis is to make explicit use of the reward function, instead of only gathering function evaluations of it, that come as part of a transition sample.
-
MSc: Experience replay for efficient online reinforcement learning
Start: October 2007 End: October 2008
Participants: Sander Adam, MSc student (graduated cum laude); Lucian Busoniu, co-advisor; Prof. Robert Babuska, advisor.

Description: Although Reinforcement Learning (RL) is guaranteed to give an optimal controller for many control problems, its practical use is limited due to its slow learning performance. This paper introduces a new class of algorithms which dramatically speeds up learning performance, at moderate computational cost. Opposed to traditional RL algorithms which use each data sample only once, the newly introduced algorithms repeatedly present all collected data samples to the learning controller in a process named experience replay (ER). The use of experience replay in RL has only been researched in some very specific applications, and has never been used as the main learning mechanism. Analysis shows that the ER algorithms learn fast, are computationally efficient and scale up well to multidimensional state-spaces. The ER algorithms are tested on a pendulum swing-up task, both in simulation and in reality. In simulation, the ER algorithms outperform a least-squares policy iteration controller in terms of learning speed and computational complexity. The ER algorithms also perform well on the real pendulum swing-up setup, where they successfully learn to swing up within 100 s. The application on a two-link robotic manipulator simulation shows the ability of the ER algorithms to scale up well to larger state-action spaces. Finally, high performance is obtained on a real robotic goalkeeper setup, illustrating the applicability of ER algorithms to practical control problems.
Watch on YouTube:
-
MSc: Using prior knowledge to accelerate reinforcement learning
Start: August 2007 End: June 2008
Participants: Maarten Vaandrager, MSc student (graduated cum laude); Lucian Busoniu, co-advisor; Prof. Robert Babuska, advisor.
Description: A RL controller learns an optimal policy by online (real-time) exploration of the control task. Usually, RL algorithms take a long time to converge. This is an important obstacle preventing the application of RL to real-life problems. This project investigates ways to speed up the convergence of RL algorithms by using prior knowledge about the controlled process or about the solution. Several new architectures of actor-critic learning are proposed, making use of locar linear regression as an approximator. Then, prior knowledge about the process and solution is added to these algorithm, in the non-parameteric form of measurement samples. The resulting algorithms give better performance in simulation examples that the original algorithms, which did not use prior knowledge.
Watch movies showing:
- Learning how to swing up an inverted pendulum with model-based imitation (no RL), from this demonstrated behavior.
- Imitation learning for a robotic arm (including demonstrations), and additional behaviors, showing also how the algorithm handles trajectory interruptions.
- Simulated inverted pendulum swingup using classical actor-critic RL.
- Actor-critic RL with a learned process model in the same problem, leading to much faster learning.
- Actor-critic RL with model-based imitation in the same problem.