Lecturer: Lucian Busoniu
Navigation: [Lecture slides|Labs|Contact] [Back to the lecturer's webpage]
This course provides methods for controlling systems that are too complex or insufficiently known to apply classical control design techniques. The focus is placed on learning algorithms for control, in particular reinforcement learning (RL). Attention is also paid to model-based techniques related to RL, as they can be very useful in controlling complex systems even when a model is known. After introducing the RL problem, the dynamic programming algorithms that sit at the foundation of RL are described in the discrete-variable context. Then, classical RL algorithms are introduced in the same context. In the second part of the course, the dynamical programming and RL algorithms are extended with approximation techniques, in order to make them applicable to continuous-variable control, as well as to large-scale discrete-variable problems. We dedicate significant space to deep reinforcement learning techniques.
This course is part of the Master program ICAF of the Automation Department, UTCluj (1st year 2nd semester). As prerequisites, basic knowledge of analysis and linear algebra is needed, together with notions of discrete-time dynamical systems. The teacher responsible is Lucian Busoniu.
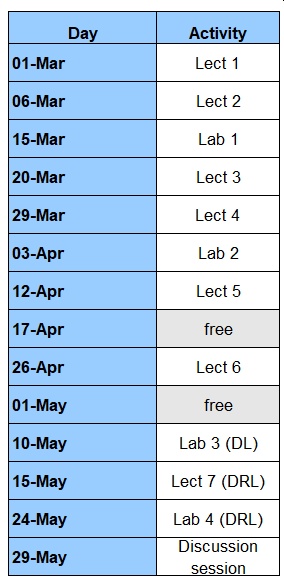
The lecture and lab sessions take place on Wednesdays and Mondays, alternating weeks, from 18:00 in room C12. A detailed schedule is given next (updated April 6th 2023):
Grading rules:
The slides are made available here in time for each lecture. The slides are required material for the exam. They, as well as the lectures, are in Romanian.
In the lab classes, a set of assignments must be solved. A solution consists of a brief report in PDF and associated code, and must be submitted by a specified deadline. For each lab, the full code or a specified part of it should be completed during the lab session itself. Each lab is graded up to 10, reduced to 5 if handed in late. The Matlab labs are required to participate in the exam.
There is zero tolerance for copying; any copied solution means immediate forfeiture of the discipline for this year.
A discussion session with mandatory participation will be organized before the exam (the exact date will be announced later), where the teachers will discuss the solutions separately with each student group. In this session, detailed questions will be asked to clearly assess whether the assignment solution is original, and the contribution of each student to this solution.
Comments, suggestions, questions etc. related to this course or website are welcome; please contact the lecturer.